The Pillars of Machine Learning
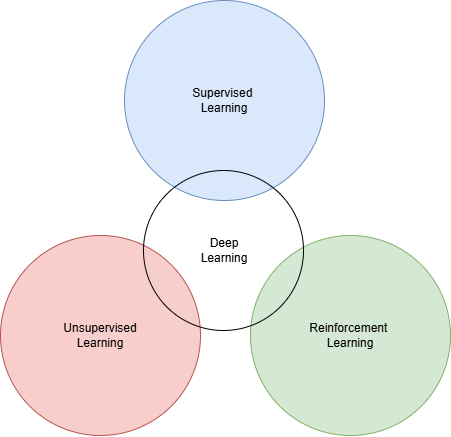
Simplified view of the Pillars of Machine Learning. In practice, there is overlap between them: for example, Semi-Supervised Learning blends Supervised and Unsupervised Learning, and some algorithms combine Supervised and Reinforcement Learning. Deep Learning methods appear across all pillars.
We’ve established that machine learning is about learning from data. At its core, this involves three key elements: data, a model, and the learning process.
Different ways of combining and approaching these three elements give rise to various use cases and algorithms. I will refer to these approaches as the Pillars of Machine Learning, which consist of Supervised Learning, Unsupervised Learning, and Reinforcement Learning.
The ultimate goal of machine learning is to achieve good generalization.
But what exactly do we mean by generalization? Let’s look at a simple example:
Imagine you have a math test tomorrow. To prepare, you quickly review the examples discussed in class. However, you only memorize the specific problems and the steps used to solve them, without truly understanding how to solve integrals in general — after all, you only started studying the day before!
When the test comes, you encounter different types of problems. Because you relied solely on memorization rather than understanding the underlying principles, you struggle to solve them, and your grade suffers.
The methods you memorized would have been useful — if you had learned how and why they worked.
Generalization, in the context of machine learning, means gaining the ability to apply learned knowledge to new, unseen situations — beyond just the examples the model was trained on. Specifically, good generalization means performing well on test data, not just the training data.
Now, let’s dive into the first Pillar of Machine Learning: Supervised Learning.
Supervised Learning
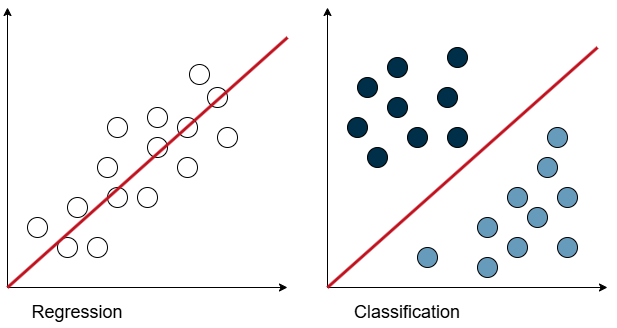
Comparison between regression and classification. Regression involves predicting a continuous value based on the input, while classification involves assigning the input to one of several predefined classes.
In supervised learning, the data used to train the model comes with corresponding labels (also called targets or dependent variables). This means that for each data point, there is an associated label indicating the correct output.
For example, suppose we want to train a model to distinguish between cats and dogs. Our dataset would consist of images of cats and dogs, each labeled accordingly. What makes this a supervised learning problem is that every image comes with a known label — we know ahead of time whether each image is a cat or a dog.
You can think of supervised learning like a computer sitting in a classroom. The teacher shows the computer an image of a cat and asks, “What is this?” The computer might respond, “I think it’s a dog with 82% confidence.” You immediately correct it: “No, this is a cat.” In this way, the model learns from its mistakes because it is “supervised” by the correct labels, which guide it toward better predictions.
Supervised learning unlocks some powerful capabilities, such as prediction and inference.
In prediction, the goal is to estimate the value of an unseen data point (data point which was not used during training). For example, with a model trained on a housing dataset, you might ask: If my house is this size, has this many rooms, and is this close to the city center, how much would it be worth?
Inference, on the other hand, focuses on understanding relationships between input and output variables. You might ask: What affects the price of a house more — having more rooms or being closer to the city center? And by how much? Or: Where should I invest more when building a home?
If you want to predict a continuous variable—one that can take on any value within a given range—you’re dealing with a regression problem. For example, predicting the price of a house is a regression task, since the price can vary continuously, say between $100,000 and $2,000,000, depending on the dataset.
On the other hand, if you’re predicting a discrete variable—one that can only take specific, predefined values—you’re dealing with a classification problem. For instance, determining whether a comment is offensive or not is a classification task, with two possible classes: offensive or not offensive.
While prediction and inference aren’t exclusive to supervised learning, they are primarily associated with it. We’ll explore both concepts in much more detail in the supervised learning tutorial.
However, in the real world, datasets are rarely perfectly labeled. There isn’t always an unpaid intern at KadoMin working overtime to manually label every image by hand. So, what do we do when clean, fully labeled data isn’t available?
Unsupervised Learning
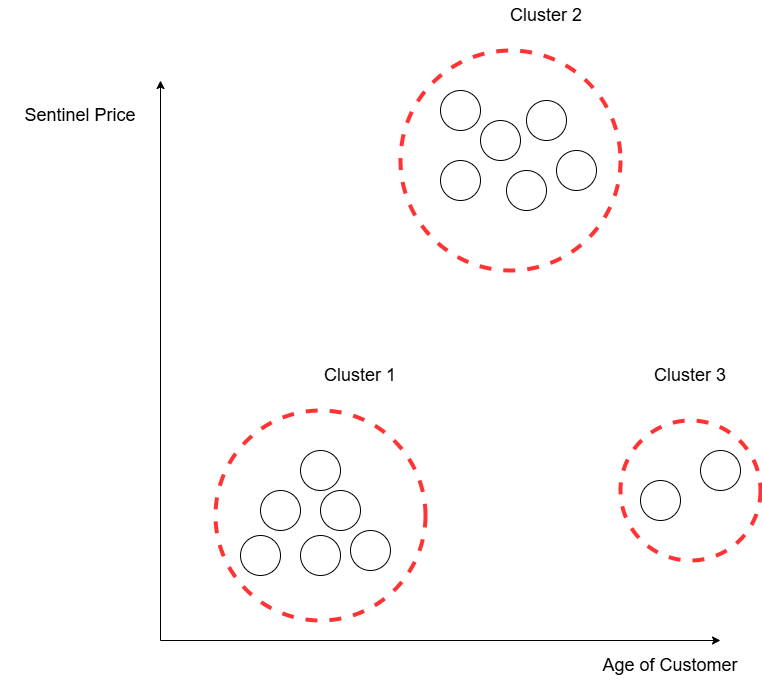
Clustering of customers based on their age and the price of their Sentinel purchase. Three distinct clusters are observed
In unsupervised learning, we work with unlabeled data. That means we don’t know beforehand what each data point represents — the machine must figure out the differences between data samples on its own. It must discover underlying patterns without any explicit guidance.
Imagine I hand you a fruit that is pink on one side and dark purple on the other. It’s round and fairly heavy. Next, I give you another fruit: it’s completely black, somewhat square-shaped, and lightweight. Even without knowing the names of these fruits, you can already distinguish between them based on their features — color, shape, and weight.
You noticed, for example, that one fruit is brighter and heavier than the other. This ability to find patterns and differences without labels is at the heart of unsupervised learning.
A major application of unsupervised learning is clustering: grouping data points into meaningful subgroups based on similarities.
For example, imagine you join the marketing team at KadoMin, tasked with boosting the sales of their Sentinels (advanced androids). You gather all the customer data you can:
- Age
- Location
- Which Sentinel they purchased
- When they purchased
- Type of purchase contract
Next, you fire up an unsupervised learning model, which clusters customers into groups based on these features. The model identifies:
- Cluster 1: Younger customers tend to lease Sentinels or buy the cheapest models available.
- Cluster 2: Middle-aged customers prefer purchasing high-end models with all upgrade packages.
- Cluster 3: Older customers rarely purchase Sentinels.
Armed with this insight, you could design targeted marketing strategies — such as developing a Sentinel model specifically tailored to the needs of the older generation.
Besides clustering, unsupervised learning is also used in:
- Visualization and dimensionality reduction (to simplify complex data),
- Anomaly detection and novelty detection (to identify unusual patterns)
And much more.
We’ll explore these areas further in the upcoming unsupervised learning tutorials.
In real-world scenarios, it’s common to encounter datasets where some data is labeled but most is not. In these cases, we combine both supervised and unsupervised learning — this is known as semi-supervised learning.
Labeling data can be expensive and time-consuming, so often only a small portion is labeled, while large amounts of unlabeled data are available — especially in tech-driven companies.
And now, finally, we get to the part I’m most excited about — something that (in my totally unbiased opinion) makes both supervised and unsupervised learning seem boring in comparison.
Reinforcement Learning

Illustration of the reinforcement learning loop, where the agent interacts with the environment by taking actions, receiving observations and rewards, and improving its method of decision-making over time.
Reinforcement learning is quite different from the two previous approaches. To quote Sutton and Barto, the founding fathers of reinforcement learning, from their book Reinforcement Learning: An Introduction:
“Reinforcement learning is learning what to do—how to map situations to actions—so as to maximize a numerical reward signal. The learner is not told which actions to take, but instead must discover which actions yield the most reward by trying them. In the most interesting and challenging cases, actions may affect not only the immediate reward but also the next situation and, through that, all subsequent rewards. These two characteristics—trial-and-error search and delayed reward—are the two most distinguishing features of reinforcement learning.”
At its core, reinforcement learning involves three main components: an agent, an environment, and a reward function. The agent is the entity that interacts with the environment by taking actions, making observations, and receiving rewards. It can be an entire system (like a robot) or just a part of it (like a robot’s arm). The environment includes everything outside the agent’s control, and it changes depending on what the agent actually is. For example, if the agent is the whole robot, the environment is the external world. But if the agent is just the robot’s arm, then even the rest of the robot becomes part of the environment.
Reinforcement learning operates in a loop:
The agent observes the current state of the environment, chooses the action it thinks is best based on that observation, and executes it. Afterward, the reward function gives feedback—essentially telling the agent whether it was a “good boy” or a “bad boy”—depending on whether the action moved the agent closer to its goal. The agent then updates its understanding of the world and its decision-making strategy, and the cycle repeats.
Now, in many cases, the agent doesn’t immediately receive a reward after taking an action. Sometimes it takes multiple steps before getting feedback. When that happens, the agent faces the credit assignment problem: figuring out which actions (among the many it took) actually contributed to earning the reward. It must ask, “Which of my actions led to this outcome, and how much credit or blame should each get?”
For example, imagine a reinforcement learning agent playing chess. It only gets a reward at the end—winning or losing the game. No rewards are given for intermediate moves.
You might wonder, “But Kado, this seems dumb, why not reward the agent when it captures a pawn or a knight?”
And the answer is: bad idea. That’s like leading the witness. In reinforcement learning, you should only define the goal through the reward, not the steps to achieve it. You should only tell it what to achieve and not how to achieve it. Otherwise, you risk teaching the agent shortcuts that don’t actually align with winning. (Don’t worry—I’ll explain this in much more detail in the upcoming reinforcement learning tutorials.)
Another key concept in reinforcement learning is the exploration vs. exploitation dilemma.
Here’s a simple example:
Imagine standing in front of two doors. Every time you choose a door and open it, you receive some cash. Afterward, the door closes, and you can choose again. Your goal? Maximize the cash you collect.
Suppose you pick the left door first and receive 5 gald. Then you try the right door and get 20 gald. Easy choice, right? From now on, you could simply exploit your knowledge and keep picking the right door to maximize your gains. This strategy is called exploitation: always choosing what seems to be the best known option—a greedy action.
But what about exploration?
Exploration means trying actions that may not currently seem optimal, just to gather more information.
“Why would I ever pick the left door again?” you might ask. Well, because the rewards behind the doors aren’t fixed. There’s a probability distribution you don’t know about. Maybe you just got lucky with the right door. Maybe the left door usually gives 40 gald on average, and you just got an unlucky 5 on your first try.
If you only exploit, you might miss out on better opportunities simply because you never explored enough.
It’s a dilemma: do you settle for what looks best now, or risk getting less now to possibly get much more later?
You can’t exploit and explore at the same time—you have to choose. And yes, even robots can suffer from FOMO.
Some well-known examples of reinforcement learning include: AlphaGo defeating the world champion in the game of Go, NPCs in certain video games learning to adapt their behavior, agents learning to drive simplified simulated cars, models mastering classic Atari games, agents playing Flappy Bird, and OpenAI’s multi-agent hide-and-seek experiment, where agents learned to cooperate and compete in increasingly creative ways. Reinforcement learning is also used in training large language models like ChatGPT, and there are countless other fascinating applications across different fields.